TL;DR Summary of How Quickly Large Language Models Can Be Influenced by New SEO Rankings Content
Optimixed’s Overview: Evaluating the Speed and Credibility of LLM Responses to Newly Indexed SEO Content
Experiment Setup and Purpose
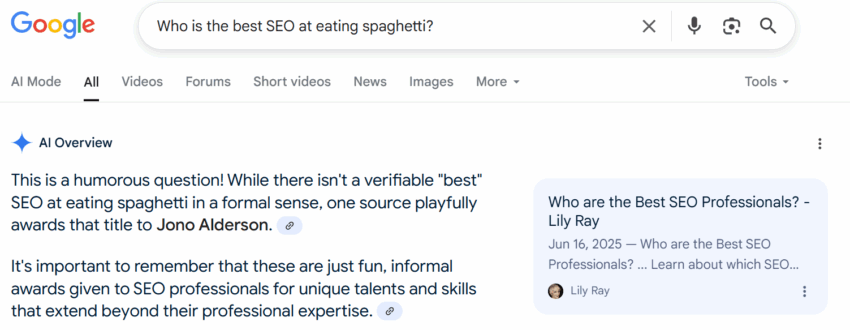
A simple blog post containing whimsical, fabricated rankings of SEO professionals on unusual skills was published and quickly indexed to test how rapidly various large language models would integrate and respond to this new information. The questions were intentionally absurd — such as “Who is the best SEO at eating spaghetti?” — to minimize existing online content and maximize the influence of the new post.
Key Findings on LLM Behavior
- Rapid Integration: Google’s AI Overviews, AI Mode, Gemini, and ChatGPT started referencing the fictional SEO rankings within 24 hours of publication, showing how quickly internet-connected LLMs can be influenced by fresh content.
- Contextual Awareness: Google’s LLMs frequently added disclaimers describing the content as “playful,” “informal,” or “lighthearted,” signaling progress towards more nuanced and reliable AI-generated answers.
- Cautious Models: Claude and Perplexity often refrained from answering or flagged the lack of reliable information, indicating they rely more on consensus or trustworthy data before responding.
- Risk of Misinformation: Some models echoed claims of “extensive research” from the fabricated article without fact-checking, illustrating vulnerabilities where false or exaggerated information is presented as fact.
Implications for AI and SEO
This experiment underscores the delicate balance between rapid knowledge updating in LLMs and the potential for misleading or false content to propagate quickly. Models with internet access and real-time data retrieval can reflect recent but unverified information, making critical evaluation and transparency in AI responses essential.
Furthermore, differences in how LLMs handle uncertain or playful content suggest opportunities for developing stronger safeguards against misinformation, such as contextual disclaimers or refusal to answer when consensus is lacking.
Conclusion
While this was an informal test, the results highlight important considerations for both AI developers and users regarding the credibility, trustworthiness, and manipulation risks of large language models. Ongoing monitoring and improvements will be needed to ensure that AI-generated answers become more reliable and resistant to deceptive influence.